| Семинары | Обучение | Лицензирование | Разработка | Подписка | Форум | Регистрация |
|

|
|
|||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||
| Вход | |||||||||||||||||||||||||||||||||
|
Раздел "Проектирование систем управления\Fuzzy Logic Toolbox"
Список функций Fuzzy Logic Toolbox В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: [V, M, obj_fcn] = fcm(X, c) Описание: На основе нечеткого c-means алгоритма выполняет кластеризацию данных. Этот алгоритм кластеризации предложил Джеймс Бэздэк (James Bezdek) в 1981 году. Задача нечеткой кластеризации ставится следующим образом. Дано:
Необходимо каждому элементу множества X поставить в соответствие степени принадлежности с классам. Элементы одного кластера должны быть так близки каждый каждому, как это только возможно, и, одновременно, кластеры должны быть на наибольшем удалении друг от друга. Для обеспечения управляемости процесса кластеризации необходимо использовать меру близости, в качестве которой обычно определяют расстояние между двумя объектами (точками в p-мерном пространстве)
Дополнительно, если функция Любое разбиение множества Обозначим через
В отличие от четкого, при нечетком c-разбиении любой объект одновременно принадлежит к различным кластерам, но с разной степенью. Условия (2) и (3) требуют только, чтобы сумма степеней принадлежности объекта ко всем кластерам была нормализована к 1, а также, чтобы количество кластеров, к которым принадлежит объект, не превышало Обозначим центры кластеров, т. е. точки в p-мерном пространстве, вокруг которых сконцентрированы соответствующие объекты, через При использовании эвклидового расстояния задача нечеткой кластеризации состоит в нахождении такой матрицы степеней принадлежности
где Значение экспоненциального веса устанавливается до начала кластеризации. Экспоненциальный вес Аналитического решения задачи нахождения оптимальных координат центров кластеров и матрицы степеней принадлежности не существует, поэтому она решается численно. Один из итерационных алгоритмов решения этой задачи реализован в функции fcm. Функция fcm может иметь три входных аргумента:
Алгоритм кластеризации останавливается когда выполнено максимальное количество итераций или когда улучшение значения целевой функции за одну итерацию меньше указанного минимально допустимого значения. Функция fcm имеет три выходных аргумента:
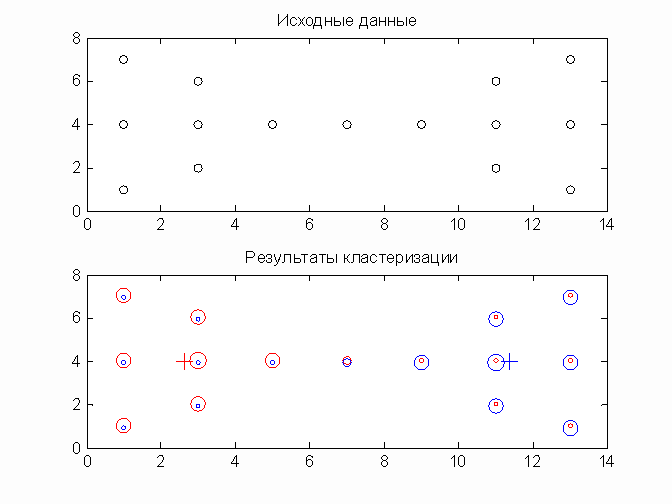
Примечание: при описании нечеткого c-means алгоритма использована книга Zimmermann H.-J. Fuzzy Set Theory - and Its Applications.3rd ed.- Kluwer Academic Publishers, 1996.- 435p. Пример. Проводится кластеризация объектов, образующих фигуру типа “бабочка”. Результаты кластеризации приведены ниже на рисунке. Центры кластеров указаны маркером ‘+’. Размер маркера ‘o’ пропорционален степени принадлежности объекта кластеру. Расположенный в центре объект имеет одинаковые степени принадлежности к красному и к синему кластерам. Это обеспечивает симметричное разбиение объектов по кластерам, что невозможно при четкой кластеризации. X=[1 1; 1 4; 1 7; 3 2; 3 4; 3 6; 5 4; 7 4; 9 4; 11 2; 11 4; 11 6; 13 1; 13 4; 13 7];
|
|
Всероссийская научная конференция "Проектирование научных и инженерных приложений в среде MATLAB" (май 2002 г.)
|
||
| На первую страницу \ Сотрудничество \ MathWorks \ SoftLine \ Exponenta.ru \ Exponenta Pro | ||
| E-mail: | ||
| Информация на сайте была обновлена 11.05.2004 |
Copyright 2001-2004 SoftLine Co Наши баннеры |
|
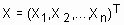 – объекты, подлежащие кластеризации (n – количество объектов). Каждый объект
– объекты, подлежащие кластеризации (n – количество объектов). Каждый объект 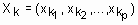 представляет собой точку в p-мерном пространстве признаков (
представляет собой точку в p-мерном пространстве признаков (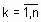 );
);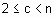 ).
).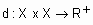 , такой что:
, такой что: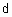 удовлетворяет правилу треугольника, т. е.
удовлетворяет правилу треугольника, т. е. 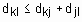 , тогда эта функция является метрикой, хотя выполнения этого свойства не всегда необходимо для задач кластеризации.
, тогда эта функция является метрикой, хотя выполнения этого свойства не всегда необходимо для задач кластеризации.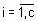 ) может быть полностью описано функцией принадлежности
) может быть полностью описано функцией принадлежности 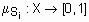 .
.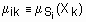 , и через
, и через 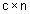 . Тогда нечетким c-разбиением (или матрицей степеней принадлежности) называется матрица
. Тогда нечетким c-разбиением (или матрицей степеней принадлежности) называется матрица 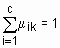 ,
, 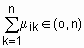 ,
, 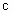 .
.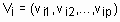 ,
, 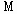 и таких координат центров кластеров
и таких координат центров кластеров 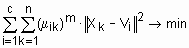 ,
, - центр i-го кластера,
- центр i-го кластера, 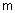 - так называемый экспоненциальный вес (
- так называемый экспоненциальный вес (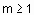 ).
).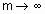 она примет вид
она примет вид